NVIDIA just outperformed by nearly 20x the record for running the standard big data analytics benchmark, known as TPCx-BB.
Using the RAPIDS suite of open-source data science software libraries powered by 16 NVIDIA DGX A100 systems, NVIDIA ran the benchmark in just 14.5 minutes, versus the current leading result of 4.7 hours on a CPU system. The DGX A100 systems had a total of 128 NVIDIA A100 GPUs and used NVIDIA Mellanox networking.
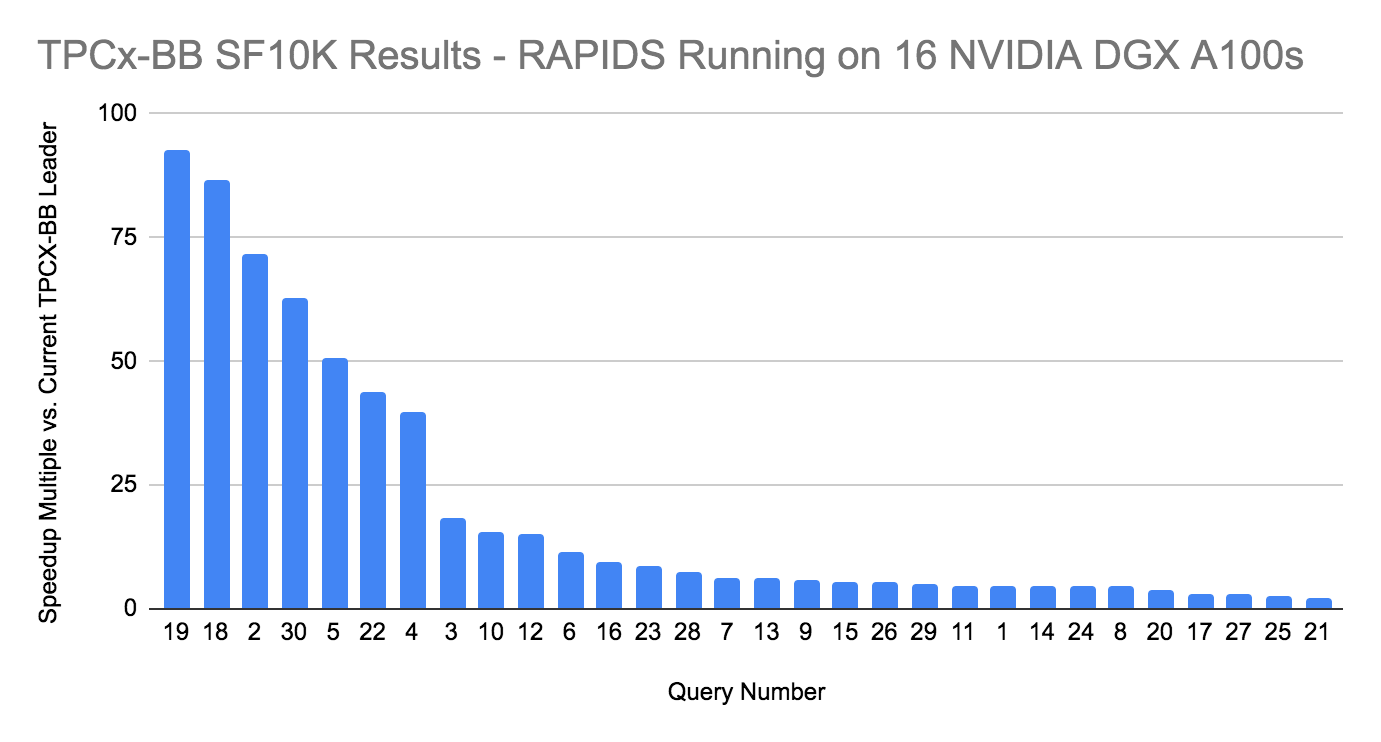
Software and Hardware Align for Full-Throttle Results
Today, leading organizations use AI to gain insights. The TPCx-BB benchmark features queries that combine SQL with machine learning on structured data, with natural language processing and unstructured data, reflecting the diversity found in modern data analytics workflows.
These unofficial results point to a new standard, and the breakthroughs behind it are available through the NVIDIA software and hardware ecosystem.
To run the benchmark, NVIDIA used RAPIDS for data processing and machine learning, Dask for horizontal scaling and UCX open source libraries for ultra fast communication, all supercharged on DGX A100.
DGX A100 systems can effectively power analytics, AI training and inference on a single, software-defined platform. DGX A100 unites the NVIDIA Ampere architecture-based NVIDIA A100 Tensor Core GPUs and NVIDIA Mellanox networking in a turnkey system that scales with ease.
Parallel Processing for Unparalleled Performance
TPCx-BB is a big data benchmark for enterprises representing real-world ETL (extract, transform, load) and machine learning workflows. The benchmark’s 30 queries include big data analytics use cases like inventory management, price analysis, sales analysis, recommendation systems, customer segmentation and sentiment analysis.
Despite steady improvements in distributed computing systems, such big data workloads are bottlenecked when running on CPUs. The RAPIDS results on DGX A100 showcase the breakthrough potential for TPCx-BB benchmarks powered by GPUs, a measurement historically run on CPU-only systems.
In this benchmark, the RAPIDS software ecosystem and DGX A100 systems accelerate compute, communication, networking and storage infrastructure. This integration sets a new bar for running data science workloads at scale.
Efficient Benchmarking at Big Data Scale
At the SF10000 TPCx-BB scale, the NVIDIA testing represents results for a workload with more than 10 terabytes of data.
At this scale, query complexity can quickly drive up execution time, which increases data center expenses like space, server equipment, power, cooling and IT expertise. The elastic DGX A100 architecture addresses these challenges.
And with new NVIDIA A100 Tensor Core GPU systems coming from NVIDIA hardware partners, data scientists will have even more options to accelerate their workloads with the performance of A100.
Open Source Acceleration and Collaboration
The RAPIDS TPCx-BB benchmark is an active project with many partners and open source communities.
The TPCx-BB queries were implemented as a series of Python scripts utilizing the RAPIDS dataframe library, cuDF; the RAPIDS machine learning library, cuML; and CuPy, BlazingSQL and Dask as the primary libraries. Numba was used to implement custom logic in user-defined functions, with spaCy for Named Entity Recognition.
These results would not be possible without the RAPIDS and broader PyData ecosystem.
To dive deeper into the RAPIDS benchmarking results, read the RAPIDS blog. For more information on RAPIDS, visit rapids.ai.
The post NVIDIA Shatters Big Data Analytics Benchmark appeared first on The Official NVIDIA Blog.


by Scott McClellan via The Official NVIDIA Blog



No comments: